Advertisement

Explore how to turn your ML script into a scalable app using Streamlit for the UI, Docker for portability, and GKE for deployment on Google Cloud

What if online shopping felt like a real conversation? Shopify’s new AI agents aim to replace filters and menus with smart, personalized chat. Here’s how they’re reshaping ecommerce

Discover how ServiceNow uses AI to boost ROI, streamline workflows, and transform digital operations across your business
Learn how machine learning predicts product failures, improves quality, reduces costs, and boosts safety across industries

Learn best practices for auditing AI systems to meet transparency standards and stay compliant with regulations.

Learn the regulatory impact of Google and Meta antitrust lawsuits and what it means for the future of tech and innovation.

CyberSecEval 2 is a robust cybersecurity evaluation framework that measures both the risks and capabilities of large language models across real-world tasks, from threat detection to secure code generation

Learn everything about mastering LeNet, from architectural insights to practical implementation. Understand its structure, training methods, and why it still matters today

What sets Meta’s LLaMA 3.1 models apart? Explore how the 405B, 70B, and 8B variants deliver better context memory, balanced multilingual performance, and smoother deployment for real-world applications

How to merge two dictionaries in Python using different methods. This clear and simple guide helps you choose the best way to combine Python dictionaries for your specific use case

How the Artificial Analysis LLM Performance Leaderboard brings transparent benchmarking of open-source language models to Hugging Face, offering reliable evaluations and insights for developers and researchers
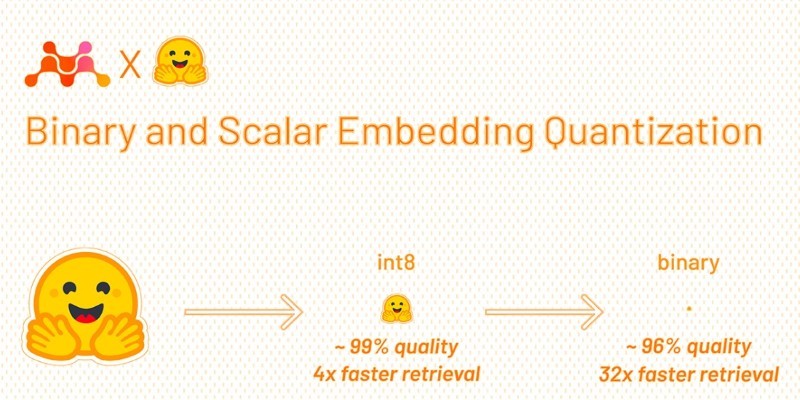
How Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval helps reduce memory use, lower costs, and improve search speed—without a major drop in accuracy
The ways we evaluate artificial intelligence have often been limited to final answers. You ask a model a question, it responds, and its success is judged by whether that answer is correct. But intelligence isn’t just about right or wrong—it’s about how a response is built. That’s where the Open Chain of Thought Leaderboard comes in.
Instead of focusing only on outcomes, this initiative puts the spotlight on reasoning steps, examining how AI systems think, not just what they conclude. It's a shift that encourages transparency, better design choices, and a deeper understanding of AI behaviour.
The Open Chain of Thought Leaderboard is a public benchmark created to evaluate how well AI models perform chain-of-thought (CoT) reasoning. Chain-of-thought refers to the intermediate reasoning steps an AI model generates before reaching a final answer. These steps give insight into how the model processes information, connects facts, handles ambiguity, and makes logical progress.
Unlike most standard leaderboards that simply concentrate on accuracy scores, the Open Chain of Thought Leaderboard is more process-focused. It doesn't merely probe whether the response is correct—it probes how the model arrived there and if that route was sane, consistent, and human-like.
Organized as an open-source initiative and backed by funding from researchers, developers, and the wider AI community through their contributions, the leaderboard seeks to provide a platform for models to be benchmarked on reasoning quality, not merely performance. It does this through both automated and human-in-the-loop tests, assisting in providing a complete picture of model behaviour.
The push toward chain-of-thought reasoning in AI has been building for some time. Large language models have become increasingly good at producing coherent, step-by-step answers when prompted correctly. This shift enables them to solve complex tasks, such as math problems, logical puzzles, or multi-step questions, that would trip up simpler models.

The logic is simple: when a model lays out its thinking, there is a better chance of catching errors, understanding failures, and improving the design. This mirrors how humans approach problems—we explain our reasoning, not just the answer. The chain-of-thought process allows researchers to analyze where things go wrong. Did the model make a faulty assumption halfway through? Did it skip a step or misinterpret a key detail? These issues are invisible in a final-answer-only evaluation system.
Moreover, CoT outputs help build trust. When users can see why a model made a particular choice, it becomes easier to accept its decisions—or challenge them if they don’t hold up. This is especially important in areas like education, legal reasoning, or healthcare, where transparency can’t be an afterthought.
The Open Chain of Thought Leaderboard is structured around carefully selected datasets that require reasoning beyond factual recall. These include problems in mathematics, science, logic, and language understanding. Each dataset is chosen not only for difficulty but also for how well it exposes different kinds of reasoning paths.
To appear on the leaderboard, models are submitted along with their reasoning traces for each problem. These traces are then evaluated in a few different ways:
First, there’s an automated scoring system. This looks at the logical consistency of the chain, its alignment with the final answer, and whether the steps follow a valid reasoning trajectory. For example, did the model perform the correct operations in the right order? Did it use relevant facts? Was the reasoning redundant, circular, or confusing?
Second, selected examples are reviewed by human judges. These reviewers look for clarity, logical flow, and coherence. A good chain-of-thought output doesn’t just get the job done—it does so in a way that makes sense to a human reader.
What sets this leaderboard apart is its openness. Anyone can submit a model, review existing outputs, or propose changes to evaluation criteria. This transparency allows for community involvement and ongoing improvement. It also prevents the leaderboard from becoming outdated, as new reasoning styles and evaluation challenges can be incorporated without waiting for a complete overhaul.
The Open Chain of Thought Leaderboard isn’t just a tool for ranking models—it’s a shift in how we think about AI performance. It encourages researchers to focus on models that not only produce correct answers but do so in understandable, rational ways. This has several ripple effects across the field.

First, it fosters the development of better training techniques. Models that learn to reason step-by-step are often more reliable and robust. Researchers may use the leaderboard data to refine their prompts, improve few-shot learning strategies, or design new architectures that favor sequential thinking.
Second, it promotes accountability. As AI systems are used in more sensitive and impactful roles, showing their work becomes less of a luxury and more of a necessity. A model that can’t explain itself—or whose reasoning fails under scrutiny—may not be trusted, even if its outputs are sometimes correct.
Third, the leaderboard helps detect biases and flaws that could otherwise go unnoticed. A model that gives a correct answer for the wrong reasons is still making a mistake, and those mistakes can propagate into real-world errors if left unchecked. Chain-of-thought analysis makes it easier to identify these patterns and address them at the source.
And finally, this initiative opens the door for better human-AI collaboration. If we want to work alongside AI models, we need to understand how they think. The Open Chain of Thought Leaderboard brings that understanding closer by turning the spotlight onto the reasoning process itself.
The Open Chain of Thought Leaderboard marks a meaningful step toward better AI evaluation. By focusing on reasoning instead of just final answers, it helps expose how models think, where they go wrong, and how they can be improved. It promotes transparency, invites collaboration, and supports more responsible AI development. As these systems become more embedded in daily life, understanding their thought process becomes essential. This leaderboard isn’t just a metric—it’s a mindset shift toward AI that can reason clearly, explain itself, and earn trust through its logic, not just its results.