Advertisement
Learn how machine learning predicts product failures, improves quality, reduces costs, and boosts safety across industries

How to run ComfyUI workflows for free using Gradio on Hugging Face Spaces. Follow a step-by-step guide to set up, customize, and share AI models with no local installation or cost

Explore Idefics2, an advanced 8B vision-language model offering open access, high performance, and flexibility for developers, researchers, and the AI community

How the Open Medical-LLM Leaderboard ranks and evaluates AI models, offering a clear benchmark for accuracy and safety in healthcare applications

CyberSecEval 2 is a robust cybersecurity evaluation framework that measures both the risks and capabilities of large language models across real-world tasks, from threat detection to secure code generation

How to manipulate Python list elements using indexing with 9 clear methods. From accessing to slicing, discover practical Python list indexing tricks that simplify your code

How the Artificial Analysis LLM Performance Leaderboard brings transparent benchmarking of open-source language models to Hugging Face, offering reliable evaluations and insights for developers and researchers

Learn the regulatory impact of Google and Meta antitrust lawsuits and what it means for the future of tech and innovation.

How to fix attribute error in Python with easy-to-follow methods. Avoid common mistakes and get your code working using clear, real-world solutions

What if online shopping felt like a real conversation? Shopify’s new AI agents aim to replace filters and menus with smart, personalized chat. Here’s how they’re reshaping ecommerce
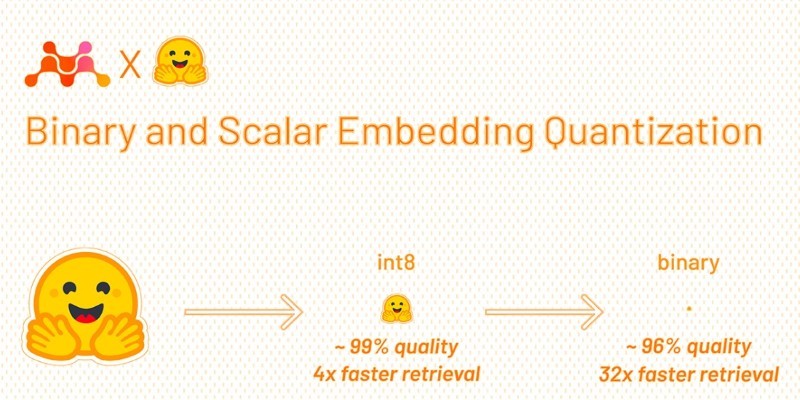
How Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval helps reduce memory use, lower costs, and improve search speed—without a major drop in accuracy

Explore how to turn your ML script into a scalable app using Streamlit for the UI, Docker for portability, and GKE for deployment on Google Cloud
Every machine learning model trying to understand human language needs a way to convert words into numbers. That’s where embeddings come in. They take sentences and turn them into dense numerical vectors that represent meaning. Whether you’re working on a semantic search engine, a chatbot, or a document clustering tool, embeddings form the base of it all.
Sentence Transformers v3 offers a practical and modern approach to training and fine-tuning embedding models. It's been reworked to keep up with larger transformer models, longer sequences, and real-world training setups. If you're serious about customizing embeddings for your task, understanding how to work with Sentence Transformers v3 is key.
Sentence Transformers v3 is a significant update over earlier versions. It introduces several structural changes that are less about buzz and more about making the training process more predictable, scalable, and useful for production. The biggest shift lies in how models are built and trained. Instead of wrapping a Hugging Face transformer into a sentence embedding framework, v3 leans on the full Hugging Face Trainer setup.
This change allows much better support for distributed training, mixed-precision (FP16), and easier deployment. You're not locked into a specific pooling layer or sentence-level logic anymore. You can define custom model architectures with more flexibility, which is useful if your task requires more than a single-vector sentence representation.
Training now happens using Hugging Face's datasets and Transformers infrastructure, which means if you're already using Hugging Face tools, integrating sentence-level embedding models just got simpler. You still get smart pooling methods like mean pooling or CLS token extraction, but you can now fully customize this part, too. That flexibility matters in niche use cases, like multilingual setups or domain-specific document embeddings.
Training a model from scratch isn’t the default route for most. But if your domain includes technical jargon, uncommon sentence structures, or low-resource languages, it might be worth it. Sentence Transformers v3 makes this possible without requiring you to rewrite training loops from scratch.

First, start by picking a pre-trained transformer backbone. It doesn't need to be a sentence transformer — any Hugging Face model will do. This allows you to use popular options like bert-base-uncased, roberta-base, or even deberta-v3-large. Then, you decide how to pool the token-level outputs. Mean pooling is a good starting point for most tasks.
Next, set up your dataset. Sentence Transformers v3 works well with pairwise or triplet data for contrastive learning. With the Hugging Face datasets library, you can stream or load large datasets and apply on-the-fly tokenization. The framework includes SentenceTransformerDataset and other helpers to speed up this stage.
The main training step is handled through the Hugging Face Trainer class, which now supports most Sentence Transformers scenarios. You define your training arguments, loss function (like CosineSimilarityLoss), and evaluation logic. There’s no need for a custom loop unless your task really demands one.
Training from scratch does take time and compute, but it’s where you get the most control. You can build a domain-specific model that’s hard to beat with generic embeddings.
If you're not dealing with a rare domain or language, finetuning is usually more efficient. It lets you adapt general-purpose sentence transformers to your specific task using less data and fewer resources. Sentence Transformers v3 supports this cleanly using the same Trainer setup.
You begin with a model like sentence-transformers/all-MiniLM-L6-v2 or a multilingual variant, such as paraphrase-multilingual-MiniLM-L12-v2. These models already provide solid embeddings for general-purpose tasks.
Next, you prep your training data. If you're working on a semantic search task, your dataset might be question–answer pairs. For paraphrase detection, use sentence pairs with similarity labels. If your goal is clustering or classification, you might include label supervision directly.
The biggest benefit of finetuning with v3 is its support for contrastive losses combined with flexible batching and mixed precision. You can quickly train on a small GPU and still get high-quality results. During training, you can monitor metrics like cosine similarity or MSE between embeddings to understand how much your model is improving.
If your dataset is large, Sentence Transformers v3 works well with multi-GPU setups. With DeepSpeed or Accelerate, you can train larger models like roberta-large on longer sequences without running into memory issues. And because it’s built on top of Hugging Face tools, switching between CPU and GPU, or between cloud and local environments, is easy.
Once your model is trained or finetuned, exporting and using it is simple. Sentence Transformers v3 allows you to save the model in Hugging Face format, which means it can be loaded with a single line of code using the AutoModel and AutoTokenizer classes.

For inference, batching is important. Whether you're embedding one document or a thousand, efficient tokenization and GPU inference can save time. Sentence Transformers v3 supports both PyTorch and ONNX export, so you can run your model even in production environments that don’t use Python.
If your task involves real-time search, pair the embeddings with vector databases like FAISS or Qdrant. Sentence Transformers v3 produces dense embeddings that work well for approximate nearest neighbour search, making it easy to build fast and accurate retrieval systems.
And if you're using a pipeline architecture, you can plug your embedding model into a retrieval-augmented generation (RAG) system, reranked, or even as part of a hybrid search engine. Finetuned embeddings often outperform default ones here, especially when tailored to your document structure or user queries.
Sentence Transformers v3 brings needed flexibility and better integration into modern NLP workflows. Whether you're training embeddings from scratch or finetuning a strong base model, it simplifies the process without sacrificing control. Shifting to the Hugging Face Trainer setup opens the door for scalable, production-ready training while keeping things accessible. With support for custom architectures, domain-specific datasets, and efficient deployment, it’s well-suited for both research and real-world tasks. You don’t need massive resources to build useful embedding models anymore—you just need the right tools, and v3 delivers them in a way that’s both practical and adaptable.