Advertisement
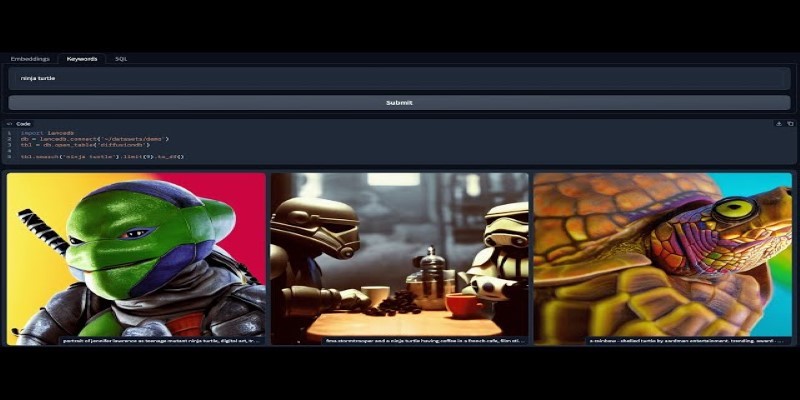
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup

Discover Midjourney V7’s latest updates, including video creation tools, faster image generation, and improved prompt accuracy

How the NumPy argmax() function works, when to use it, and how it helps you locate maximum values efficiently in any NumPy array

Discover how Nvidia continues to lead global AI chip innovation despite rising tariffs and international trade pressures.

Learn how to build a resume ranking system using Langchain. From parsing to embedding and scoring, see how to structure smarter hiring tools using language models

Learn everything about mastering LeNet, from architectural insights to practical implementation. Understand its structure, training methods, and why it still matters today
Learn everything you need to know about training and finetuning embedding models using Sentence Transformers v3. This guide covers model setup, data prep, loss functions, and deployment tips

ChatGPT in customer service can provide biased information, misinterpret questions, raise security issues, or give wrong answers
Learn how machine learning predicts product failures, improves quality, reduces costs, and boosts safety across industries

Explore the concept of global and local variables in Python programming. Learn how Python handles variable scope and how it affects your code

Discover 7 practical ways to get the most out of ChatGPT-4 Vision. From reading handwritten notes to giving UX feedback, this guide shows how to use it like a pro

How the Open Chain of Thought Leaderboard is changing the way we measure reasoning in AI by focusing on step-by-step logic instead of final answers alone
The world of artificial intelligence is rapidly becoming more involved in healthcare, and not just behind the scenes. With the arrival of large language models (LLMs) like GPT-4, Med-PaLM, and others, there's growing interest in how well these models perform on medical tasks. However, unlike general-purpose models that are tested on everything from poetry to programming, models built for medicine require a different standard. That's where the Open Medical-LLM Leaderboard comes in. It acts as a testing ground, showing in plain terms which models can handle real-world medical challenges—and which ones fall short.
The Open Medical-LLM Leaderboard is an open benchmarking platform that evaluates and ranks large language models based on their performance in medical tasks. It’s part of a larger push toward transparency and measurable progress in medical AI. Developed and maintained by Hugging Face and other contributors from the open-source AI community, this leaderboard is not just about putting models in order. It’s about identifying which systems are safe, accurate, and reliable enough to be used—or at least studied—in clinical and research settings.

This leaderboard uses a set of standardized tests made up of publicly available medical datasets. These include real-world questions from the United States Medical Licensing Examination (USMLE), medical QA datasets like MedQA, PubMedQA, and others designed to assess factual accuracy, reasoning ability, and domain knowledge. It evaluates models under uniform conditions to eliminate bias and inconsistencies. This method ensures that scores are comparable and genuinely reflect a model’s medical understanding rather than just its general linguistic skills.
What makes the leaderboard particularly valuable is its openness. Anyone can submit a model for evaluation. Anyone can view the results. That transparency is rare in a field where many tools are either hidden behind paywalls or accessible only to insiders.
Language models trained for general tasks can generate fluent and impressive text, but fluency isn't the same as correctness—especially in medicine. Saying something in a confident tone doesn't make it true. In medical contexts, wrong answers can lead to dangerous outcomes. That’s why benchmarks focused on medical use are essential. They test not just if a model can sound smart but whether it actually knows what it's talking about.
The Open Medical-LLM Leaderboard tries to capture this difference. It isn't only asking questions to see if the model can regurgitate memorized facts. It often tests how well the model understands the relationships between symptoms and diagnoses or if it can correctly assess treatment options based on clinical scenarios. These are layered tasks that require more than surface-level information.
There's also the issue of hallucinations—when models make up facts or references. In general-purpose chat, this might be harmless or even amusing. However, in medicine, inventing a treatment or misrepresenting a condition is a serious matter. Part of the leaderboard's challenge is measuring how often these hallucinations occur and how much they affect the quality of the model's output.
The primary beneficiaries are researchers, developers, and clinicians who want to understand the capabilities and limitations of medical LLMs before integrating them into practice. For example, a hospital exploring AI for patient triage might look at the leaderboard to choose a model that shows a balance of accuracy, context awareness, and stability under pressure. Academic researchers use the scores to compare approaches, test fine-tuned variants, or analyze model failure cases.

Developers of LLMs also gain valuable feedback from leaderboard results. It acts as a public report card, showing how well their models perform against others and offering clues on where to improve. This feedback loop is vital in a field where the stakes are high, and the margin for error is low.
The broader open-source community also benefits. Instead of starting from scratch, contributors can build upon models that perform well in the leaderboard, using proven baselines for future work. It encourages collaboration by lowering the entry barrier to AI in medicine.
Patients, while not the direct audience of the leaderboard, are the ultimate end-users. If this system leads to better diagnostic assistants, safer clinical decision tools, or more informative patient chatbots, then patients benefit indirectly through improved healthcare experiences and outcomes.
Even with its usefulness, the Open Medical-LLM Leaderboard isn’t perfect. First, benchmarks can only test what they’re designed to test. If a dataset focuses mostly on multiple-choice questions, it might not reflect real patient interactions, which are messy, emotional, and often incomplete. A model that performs well in controlled settings might still struggle when faced with ambiguous symptoms or non-standard cases.
Second, many medical datasets used in these benchmarks are based on English and often skewed toward Western medicine. This can limit the global relevance of leaderboard results. Expanding the benchmark to include multilingual tests and data from diverse healthcare systems is a logical next step.
Another challenge is keeping up with the pace of model development. New models appear frequently, and evaluating them takes time and computing resources. Sometimes, models are fine-tuned with access to benchmark datasets, which risks inflating scores. Keeping the leaderboard honest and fair requires constant oversight and, ideally, test datasets that remain unseen until evaluation.
Still, the leaderboard is a major step toward accountability. It creates a shared space where progress can be tracked, not just claimed. Showing where a model excels and where it fails encourages thoughtful deployment rather than blind adoption.
The Open Medical-LLM Leaderboard is more than just a scoreboard. It's a public tool that gives insight into how well language models handle the serious and often complex world of medicine. It brings transparency to a fast-moving field and helps shift the focus from hype to real-world performance. Holding models accountable through clear, open benchmarks helps everyone involved in healthcare AI—researchers, developers, clinicians—make more informed decisions. It's not a final verdict on what models can or can't do, but it's a solid step toward making them safer and more useful in the context where they matter most.