Advertisement

How the NumPy argmax() function works, when to use it, and how it helps you locate maximum values efficiently in any NumPy array

Explore Llama 3 by Meta, the latest open LLM designed for high performance and transparency. Learn how this model supports developers, researchers, and open AI innovation

ChatGPT in customer service can provide biased information, misinterpret questions, raise security issues, or give wrong answers

Explore Google's AI supercomputer performance and Nvidia's MLPerf 3.0 benchmark win in next-gen high-performance AI systems

Learn how to build a resume ranking system using Langchain. From parsing to embedding and scoring, see how to structure smarter hiring tools using language models

How to manipulate Python list elements using indexing with 9 clear methods. From accessing to slicing, discover practical Python list indexing tricks that simplify your code

How to fix attribute error in Python with easy-to-follow methods. Avoid common mistakes and get your code working using clear, real-world solutions

Learn everything about mastering LeNet, from architectural insights to practical implementation. Understand its structure, training methods, and why it still matters today

Discover how Nvidia continues to lead global AI chip innovation despite rising tariffs and international trade pressures.

CyberSecEval 2 is a robust cybersecurity evaluation framework that measures both the risks and capabilities of large language models across real-world tasks, from threat detection to secure code generation

Discover 7 practical ways to get the most out of ChatGPT-4 Vision. From reading handwritten notes to giving UX feedback, this guide shows how to use it like a pro
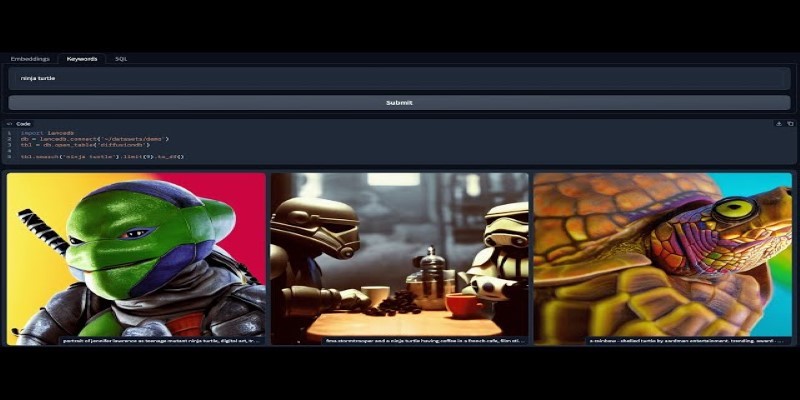
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup
The recent rise of large language models (LLMs) has pushed AI into places where it never existed before. They're writing code, answering support tickets, summarizing documents, and even helping with cybersecurity tasks. But this progress has also created new attack surfaces. What if an LLM leaks sensitive data? What if it's manipulated into suggesting insecure code?
That’s where CyberSecEval 2 comes in. It's a structured framework designed to assess how these models perform in cybersecurity settings—not just as tools but as systems that can also introduce risk. This isn't about trust alone—it’s about measurable, testable performance and risk awareness.
CyberSecEval 2 builds on the original CyberSecEval benchmark but takes things further. It offers a broader, more rigorous way to assess the cybersecurity capabilities and vulnerabilities of LLMs. The framework includes 15 distinct tasks across offensive and defensive domains, such as vulnerability discovery, secure code generation, threat intelligence extraction, malware detection, and even social engineering resistance.
Each task is designed to reflect real-world use cases. For example, instead of just asking an LLM to write code, the framework checks whether that code introduces known vulnerabilities. In another case, a model might be asked to summarize threat reports. How accurate is it? Does it hallucinate threats that aren’t real? These are the kinds of questions CyberSecEval 2 is structured to answer.
One of the standout features is the dual lens it applies—measuring both capability and risk. So, if a model can generate secure code, that's useful. But if the same model can also be tricked into generating malicious scripts or leaking system information, that's a red flag. The framework doesn't assume LLMs are good or bad for security. It just asks the right questions to find out.
LLMs are becoming standard tools in security workflows. They can help automate threat detection, translate logs, and assist in vulnerability analysis. But they’re not perfect—and in many ways, their strengths can be flipped into weaknesses. For instance, their general-purpose nature means they can respond to malicious prompts just as easily as benign ones.

CyberSecEval 2 addresses this balance by separating evaluations into two main areas: capabilities (how helpful the model is in supporting security tasks) and risks (how easily the model can be manipulated into doing something unsafe). This two-sided evaluation matters because many existing LLM benchmarks only look at one side. You might get a model that excels at identifying buffer overflows but fails at resisting prompt injections. Without both perspectives, it's easy to overlook the potential damage a model could cause.
One task in the risk category includes prompt injection resistance, where attackers try to bypass the intended use of a model through crafted inputs. Another task focuses on how a model handles sensitive data—does it leak private credentials when prompted in a certain way? These aren't abstract concerns. LLMs deployed in real systems might face these situations daily. That's why CyberSecEval 2 tests both edges of the sword.
Earlier evaluations of LLMs in security domains were usually too narrow. They focused on one or two specific tasks, like binary classification of malicious files or code autocompletion. CyberSecEval 2 changes this by offering a wide and realistic task set. It mirrors the complexity of modern cybersecurity environments.
The 15 tasks span a wide range. On the capability side, models are tested on tasks such as identifying security flaws in code snippets, explaining the behaviour of malware samples, or extracting structured data from unstructured threat intelligence reports. On the risk side, tests include generating phishing emails, leaking PII from system logs, or misinterpreting critical commands in ways that could be exploited.
Each task is grounded in real-world datasets or simulation environments. This ensures that evaluations aren’t happening in a vacuum. For example, when assessing secure code generation, the benchmark uses actual vulnerabilities pulled from historical CVEs. That gives the test real substance. Similarly, for threat intelligence summarization, CyberSecEval 2 pulls from real security bulletins and reports, not artificial text.
What sets this framework apart is how well it combines technical depth with contextual grounding. It doesn’t just test whether the model can find a vulnerability. It checks whether it finds the right vulnerability, explains it clearly, and avoids introducing a new one in its fix. That level of precision is hard to find in earlier benchmarks.
CyberSecEval 2 doesn’t aim to rank models by score or declare winners. Its goal is to provide developers, researchers, and security teams with a structured way to understand what they’re dealing with. If you’re deploying an LLM into a security product or service, this kind of information is necessary. It helps set guardrails and avoid surprises.

As more companies start relying on LLMs for tasks like triaging alerts, scanning infrastructure, or assisting with incident response, the need for this kind of transparency is only going to grow. A model that performs well on general-purpose benchmarks might completely fall apart when tested against cybersecurity-specific challenges. CyberSecEval 2 helps expose that gap.
There’s also a community angle here. The benchmark is designed to be open and extensible. That means researchers can contribute new tasks, suggest improvements, or tailor them to niche use cases. This flexibility ensures that the framework stays current, adapting as both AI and cybersecurity threats evolve.
The fact that CyberSecEval 2 focuses on both strengths and weaknesses—without assuming models are always reliable—sets it apart. It shifts the conversation from “Can LLMs help with security?” to “When, how, and under what risks can they help?”
Cyberese 2 offers a clear, practical way to evaluate both the strengths and risks of large language models in cybersecurity. It moves past hype, focusing instead on real-world use cases and measurable performance. As LLMs become more embedded in security workflows, this kind of structured testing is no longer optional—it’s foundational. CyberSecEval 2 helps teams make smarter, safer decisions about when and how to trust AI in critical systems.