Advertisement

ChatGPT in customer service can provide biased information, misinterpret questions, raise security issues, or give wrong answers

Learn how to build a resume ranking system using Langchain. From parsing to embedding and scoring, see how to structure smarter hiring tools using language models
Learn how machine learning predicts product failures, improves quality, reduces costs, and boosts safety across industries

Learn the regulatory impact of Google and Meta antitrust lawsuits and what it means for the future of tech and innovation.
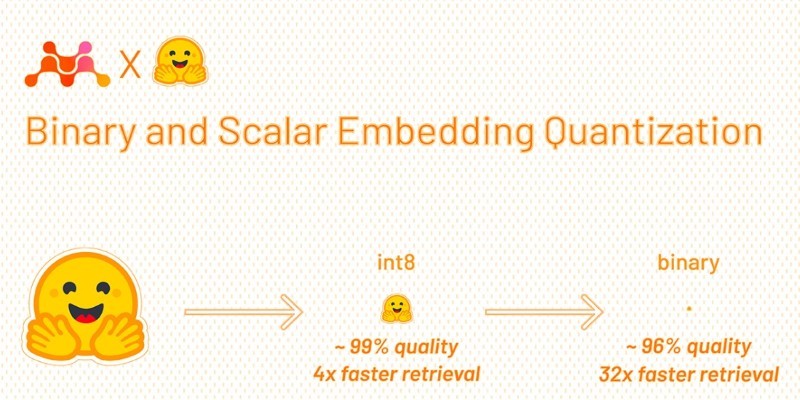
How Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval helps reduce memory use, lower costs, and improve search speed—without a major drop in accuracy
Learn what ChatGPT Search is and how to use it as a smart, AI-powered search engine

How the Artificial Analysis LLM Performance Leaderboard brings transparent benchmarking of open-source language models to Hugging Face, offering reliable evaluations and insights for developers and researchers

How the Open Medical-LLM Leaderboard ranks and evaluates AI models, offering a clear benchmark for accuracy and safety in healthcare applications
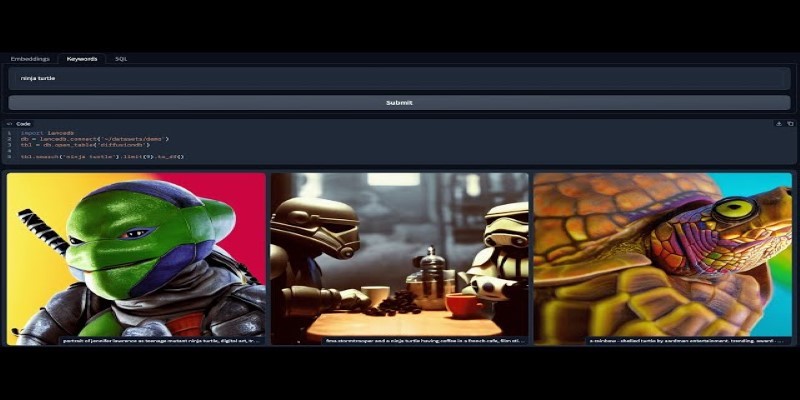
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup

Explore Idefics2, an advanced 8B vision-language model offering open access, high performance, and flexibility for developers, researchers, and the AI community

Discover 7 practical ways to get the most out of ChatGPT-4 Vision. From reading handwritten notes to giving UX feedback, this guide shows how to use it like a pro

Explore Llama 3 by Meta, the latest open LLM designed for high performance and transparency. Learn how this model supports developers, researchers, and open AI innovation
Artificial intelligence continues to grow, but many of its breakthroughs have remained in the hands of a few organizations. That's why Idefics2 stands out. Released as an open model for the public, Idefics2 brings strong capabilities in both visual and language understanding while keeping access transparent. It's a step toward providing researchers, developers, and hobbyists with the tools they need without being locked behind closed APIs or restricted platforms. This model doesn't just compete with closed systems—it shows how far open models have come and what they can do when shared with the wider community.
Idefics2 is an open-weight multimodal model that connects text and vision tasks through a single architecture. Developed by Hugging Face, it's based on a transformer design that processes both visual and language inputs. At 8 billion parameters, Idefics2 is surprisingly efficient for what it offers, delivering strong performance across various vision-language benchmarks without overwhelming hardware requirements.
The model was trained on a large amount of paired image-text data from publicly available datasets, allowing it to learn a wide range of capabilities—from understanding images to generating detailed descriptions and answering questions about them. It's not just a chatbot with picture inputs; Idefics2 is built to interpret visuals and text together in a meaningful way. Whether the task is describing a complex infographic, understanding memes, or interpreting documents that mix charts and language, the model can handle it.
One of the most notable things about Idefics2 is that it's open. Developers can download the weights, fine-tune them for their own needs, and study how it works. That's a big change from many commercial vision-language models that offer only limited API access. With Idefics2, the goal isn't just performance—it's openness, usability, and control.
At its core, Idefics2 follows a two-part structure: a visual encoder and a large language model (LLM) decoder. The visual component uses a Vision Transformer (ViT), which converts an image into embeddings—basically, a numerical summary of its features. These embeddings are then passed to the language model, which processes them along with any accompanying text. This allows Idefics2 to understand the relationship between text and visuals in a single pass.

What makes Idefics2 different is the way it handles sequences. Most multimodal models insert placeholders or use special tokens to switch between modes. Idefics2 uses a cleaner, simpler method where images are represented by fixed embeddings that slot into the input stream naturally, avoiding the need for complex token juggling. This leads to better alignment between vision and language representations.
The model supports multiple vision-language tasks. It can generate image captions, answer visual questions, analyze diagrams, and even interpret pages with both pictures and writing—like magazines or technical manuals. Idefics2 was trained on high-quality datasets such as COYO, LAION, and other open collections of image-text pairs. The training avoided synthetic datasets or private data that might skew results or raise ethical concerns. This careful curation makes it a better fit for real-world testing and safe development.
It’s also optimized for efficiency. Despite having 8 billion parameters, it runs well on high-end consumer GPUs and scales across multiple cards for larger tasks. It uses Flash Attention and other memory optimizations to speed up inference, which makes it easier to use in production settings or research environments.
Idefics2 is designed to be useful beyond benchmarks and leaderboards. Its public release means developers can integrate it into their applications, modify it, or build on top of it. Educational projects can be used to teach students about multimodal AI. Researchers can test new fine-tuning techniques or explore visual reasoning without starting from scratch.
One of the strongest points is the ability to fine-tune the model for specific tasks. Because the codebase and weights are available, teams can adapt Idefics2 to domain-specific data, such as medical imagery, satellite photos, or industrial reports. This flexibility opens up areas where general-purpose models usually fall short due to their broad training data. The open nature also means that security and bias testing are more transparent. Developers don’t have to trust a third-party’s summary—they can test the model themselves and understand its limits.
Idefics2 supports multiple frameworks, including PyTorch and Hugging Face’s own transformers library. This makes integration smoother for teams already using these tools. Prebuilt APIs and inference scripts are available, and the community around the model is growing fast, contributing tips, evaluation results, and even smaller distilled versions.
Another advantage is accessibility. Many vision-language models need expensive licenses or corporate partnerships. Idefics2 is licensed under a more permissive structure, which allows broader experimentation and product use. This opens the door for small companies, individual developers, and nonprofits to use advanced multimodal AI without legal or financial barriers.
Idefics2 signals a shift in how advanced AI is shared. Rather than being locked behind paywalls, models like this are built with openness and reuse in mind. That matters not just for technical progress but for ethical AI development. When tools are open, discussions around safety, bias, and reliability include more voices.

As developers work with Idefics2, they’ll push its boundaries, find its gaps, and improve it. That collective progress is hard to match in closed systems. It gives students, educators, and independent researchers a way to work with advanced tools.
There are trade-offs. Open models need responsible use, clear documentation, and strong community support to avoid misuse. But the foundation is solid. With reliable performance and community-first design, Idefics2 is more than just another large model—it’s a sign that vision-language tools can be shared fairly, studied openly, and built upon by anyone ready to learn.
Idefics2 marks a shift in multimodal AI by making advanced vision-language tools open and accessible. With strong performance, a clean design, and public availability, it invites real participation from developers, researchers, and curious minds. Whether for building, learning, or exploring, Idefics2 offers practical use—not just a demonstration. It signals a more inclusive future for AI development, where collaboration and transparency take priority over exclusivity and control.