Advertisement

What if online shopping felt like a real conversation? Shopify’s new AI agents aim to replace filters and menus with smart, personalized chat. Here’s how they’re reshaping ecommerce

How the NumPy argmax() function works, when to use it, and how it helps you locate maximum values efficiently in any NumPy array

Learn how to build a resume ranking system using Langchain. From parsing to embedding and scoring, see how to structure smarter hiring tools using language models

Explore the concept of global and local variables in Python programming. Learn how Python handles variable scope and how it affects your code

How the Open Chain of Thought Leaderboard is changing the way we measure reasoning in AI by focusing on step-by-step logic instead of final answers alone

What sets Meta’s LLaMA 3.1 models apart? Explore how the 405B, 70B, and 8B variants deliver better context memory, balanced multilingual performance, and smoother deployment for real-world applications

Explore Google's AI supercomputer performance and Nvidia's MLPerf 3.0 benchmark win in next-gen high-performance AI systems

Discover Midjourney V7’s latest updates, including video creation tools, faster image generation, and improved prompt accuracy
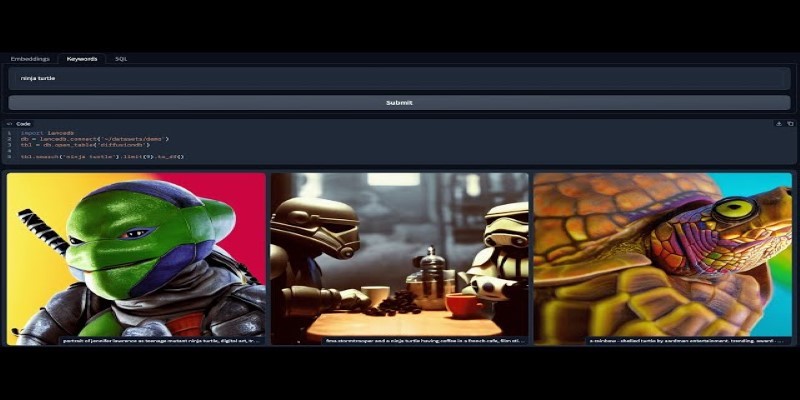
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup

How the Artificial Analysis LLM Performance Leaderboard brings transparent benchmarking of open-source language models to Hugging Face, offering reliable evaluations and insights for developers and researchers

Discover how Nvidia continues to lead global AI chip innovation despite rising tariffs and international trade pressures.

How to manipulate Python list elements using indexing with 9 clear methods. From accessing to slicing, discover practical Python list indexing tricks that simplify your code
Model collapse is becoming a major concern as AI systems increasingly rely on synthetic training data. Many models are now trained on outputs generated by other AIs instead of fresh, real-world examples. It leads to repetition, reduced precision, and a loss of originality. The influence of synthetic training data on AI algorithms has long-term consequences beyond technical concerns. The quality of data an AI model learns from directly impacts the quality of its decisions.
Training on synthetic data initiates a loop in which one AI system learns from another without human context. That is especially concerning for large-scale models that consume recycled data, prompting growing concern among AI researchers. Understanding the risks of synthetic training data, the consequences of model collapse, and how AI learning can degrade over time is increasingly important. These issues must be addressed before they compromise the safety and reliability of AI systems.

Synthetic training data refers to information generated by AI systems for use in training other AI models. Instead of real-world examples—such as human writing, images, or interactions—models are increasingly trained on synthetic data. Often, this data is derived from previous AI-generated outputs. Businesses adopt synthetic data to save time, reduce costs, and scale more efficiently. However, synthetic data lacks the richness and unpredictability of real-world content.
The diversity of training material declines. Errors from one AI system are passed on to the next, creating a chain reaction, allowing errors to proliferate across generations of models. This also narrows the knowledge base of AI systems. Although the model may appear accurate, it often merely regurgitates previously seen data. Over time, the model's performance curve flattens. Its outputs become less reliable and more prone to error. Training on synthetic inputs without proper validation often leads to biased, inaccurate, and misleading results.

The model collapse in artificial intelligence refers to the gradual deterioration of a model’s performance caused by poor-quality training data. As models rely more on synthetic data, their effective knowledge base shrinks. Instead of expanding their capabilities, they become trapped in repeating past successes. Over time, the model’s responses become narrower and more repetitive, generating nearly identical outputs for similar prompts. Novelty declines. While overall accuracy metrics may improve, performance in specialized tasks often deteriorates. This degradation is not always immediately apparent—the model may initially seem to perform well.
However, over time, underlying flaws begin to surface. Researchers have observed this phenomenon, most notably in large language models. As feedback loops form, they accelerate the onset of collapse. Models begin learning from each other’s outputs without human context or grounding. These closed training cycles prevent the incorporation of fresh, real-world data. Eventually, the AI loses its connection to real-world context and current information. For these reasons, the risks of synthetic training data are taking center stage in current AI research discussions.
AI begins to lose its ability to function effectively in the real world when trained primarily on synthetic content. The first sign is a decline in factual accuracy. AI systems begin repeating inaccurate or misleading information. They also tend to ignore or miss recent developments and current events. In customer care bots, this shows up as outdated responses. In medical tools, it results in poor analysis. The repercussions are severe. Tools for creating content seem repetitious—tools for code generation point to faulty or inadequate codes. The issue is not always obvious to casual users.
Professionals interacting with artificial intelligence, however, see the difference. Even search engines driven by artificial intelligence models begin to rank irrelevant or incorrect information. The model absorbs those mistakes when false knowledge enters training. It thus generates erroneous judgments. It also suffers from unanticipated user questions. In artificial intelligence, a model collapse results in a less flexible response of tools. Unable to adapt, the system overfits to its synthetic past. That erodes confidence and restricts AI’s application.
In artificial intelligence training, feedback loops are instances whereby the outputs of a model find value as training data. That makes models learn from their results rather than fresh data over time. The original content disappears. AI systems have started to be echo chambers. One method teaches another on the same basis. Knowledge gaps, prejudices, and mistakes go unpacked. They spread around. Over several training sessions, these loops became more intense. Researchers have characterized this as “data poisoning.”
Feedback loops rule, and artificial intelligence cannot self-correct then. The statistics get cyclical and stale. Even the greatest models start to exhibit limits. They might reply less precisely but faster. Their outputs become less varied. Synthetic training data problems stack and become more difficult to follow. Fixing them requires determining which loop part broke. That is challenging as artificial intelligence systems start depending entirely on internal outputs. Feedback loops undermine general confidence in artificial intelligence dependability, not only performance.
Researchers are developing strategies to combine synthetic and real-world data to prevent model collapse. One approach involves filtering AI-generated content before reusing it in training datasets. Another method combines synthetic outputs with carefully selected human-generated examples, lowering repetition and increasing diversity. Furthermore, researchers emphasize fine-tuning using new cases. Task-specific smaller datasets derived from actual interactions help stabilize models. Some use reverse validation when human specialists check artificial intelligence responses and eliminate faulty outcomes.
Some researchers are also developing more advanced data pipelines. These systems track the origin of synthetic outputs and prevent them from being reused repeatedly in training cycles. Another strategy involves incorporating “frozen layers” into models. These layers allow models to be updated while preserving their original knowledge base. Despite these efforts, preventing model collapse remains a significant challenge. One must be on continuous observation. Even little loops can snowball without checks. The community of artificial intelligence researchers emphasizes the need for openness.
AI systems trained on synthetic content face significant challenges in accuracy and reliability. Model collapse undermines performance, content diversity, and user trust. Without proper oversight, synthetic training data can lead to harmful feedback loops. These loops result in flawed, repetitive outputs. Researchers must combine filtered synthetic data with real-world examples to maintain AI quality. Transparency in training approaches is also essential. Crucially, the risks of synthetic training data and the need to avoid feedback loops must be clearly understood. Preventing model collapse is essential to ensure that AI continues to evolve, adapt, and behave responsibly in real-world tasks and decisions.