Advertisement

Learn best practices for auditing AI systems to meet transparency standards and stay compliant with regulations.

How to use the SQL Update Statement with clear syntax, practical examples, and tips to avoid common mistakes. Ideal for beginners working with real-world databases

How the Artificial Analysis LLM Performance Leaderboard brings transparent benchmarking of open-source language models to Hugging Face, offering reliable evaluations and insights for developers and researchers

How to merge two dictionaries in Python using different methods. This clear and simple guide helps you choose the best way to combine Python dictionaries for your specific use case

Synthetic training data can degrade AI quality over time. Learn how model collapse risks accuracy, diversity, and reliability
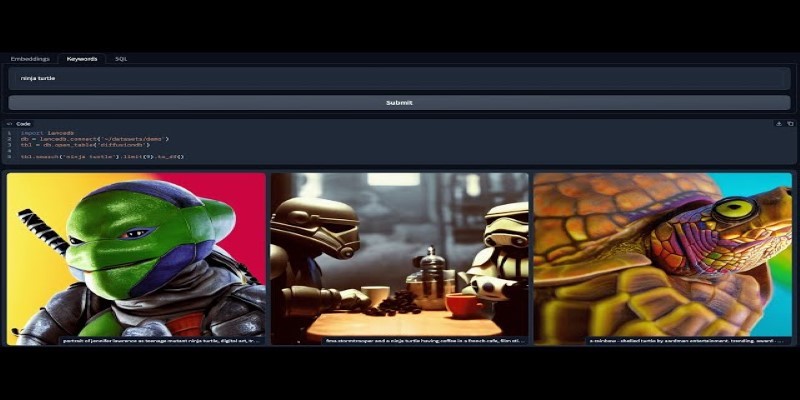
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup

How to manipulate Python list elements using indexing with 9 clear methods. From accessing to slicing, discover practical Python list indexing tricks that simplify your code

CyberSecEval 2 is a robust cybersecurity evaluation framework that measures both the risks and capabilities of large language models across real-world tasks, from threat detection to secure code generation

Explore how to turn your ML script into a scalable app using Streamlit for the UI, Docker for portability, and GKE for deployment on Google Cloud

Learn everything about mastering LeNet, from architectural insights to practical implementation. Understand its structure, training methods, and why it still matters today

Explore the concept of global and local variables in Python programming. Learn how Python handles variable scope and how it affects your code

How to run ComfyUI workflows for free using Gradio on Hugging Face Spaces. Follow a step-by-step guide to set up, customize, and share AI models with no local installation or cost
LeNet isn't new, but it still matters. Originally developed by Yann LeCun for digit recognition, it laid the groundwork for how modern convolutional networks are built. While smaller and simpler than today’s models, LeNet’s structure makes it an ideal starting point. It shows how convolution, pooling, and dense layers work together to extract features and make predictions. Many of the same ideas found in deeper architectures trace back to it. If you're looking to understand how CNNs function without getting lost in too much complexity, mastering LeNet is one of the most practical first steps you can take.
LeNet-5 takes a clean approach: two convolutional layers, each followed by subsampling, then three fully connected layers. The input is a 32x32 grayscale image. Padding is used to prevent losing edge features during the convolutions. The first convolution applies six 5x5 filters, producing six feature maps. No zero-padding reduces spatial dimensions. A 2x2 average pooling layer follows, halving the size.
Next, a second convolution uses 16 filters on selected combinations of the previous maps. Again, a 2x2 average pooling layer reduces spatial resolution. This selective connectivity reduces computation and helps capture diverse features.
The output of this layer is flattened and passed through three fully connected layers: 120 units, 84 units, and 10 output neurons representing digit classes. LeNet uses the tanh activation function throughout, consistent with practices of its time. The design is tight, clear, and intentionally minimal. The layered progression from low-level to high-level features reflects how CNNs generally process visual data. While deeper models have emerged, they often mirror this basic flow—making LeNet a structural ancestor of nearly every modern CNN.
LeNet trains fast due to its small size. On MNIST, it achieves high accuracy using modest resources. Though originally trained with vanilla stochastic gradient descent, optimizers like Adam or RMSprop work better today, offering adaptive learning rates and smoother convergence. Input standardization improves results by keeping values in a steady range, which speeds up learning.
Tanh is used throughout, though many adapt LeNet to use ReLU for faster convergence and better gradients. Dropout and batch normalization weren’t part of the original, but adding them can improve stability and performance, especially on noisier datasets. These additions help prevent overfitting without drastically changing the structure.
Loss functions also matter. For classification tasks like MNIST, cross-entropy works well. If LeNet is adapted for object detection or image segmentation, the structure needs to change, and different loss functions, such as IoU or Dice, may be used. Though built for grayscale digits, LeNet adapts easily to RGB or larger inputs by tweaking the first layer and adjusting filter sizes.
Even today, its low parameter count and fast training cycles make it ideal for experimentation, hyperparameter tuning, and optimization testing. It's simple enough for students and effective enough to serve as a strong baseline in low-power environments.
LeNet is often one of the first models implemented in code. In PyTorch, a class extending nn.Module defines its structure: two convolutional layers with pooling, followed by three dense layers. A typical forward method routes input through these layers using tanh activations.
Here’s a simple version in PyTorch:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.AvgPool2d(2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = torch.tanh(self.pool(self.conv1(x)))
x = torch.tanh(self.pool(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc3(x)
return x
TensorFlow supports a similar structure using either Sequential or Model subclassing. Layers like Conv2D, AveragePooling2D, and Dense handle the architecture cleanly. Replacing average pooling with max pooling has little impact on simple tasks like MNIST.
Both frameworks allow quick experimentation. You can add batch normalization, switch activations, or insert dropout layers to explore performance differences. With minimal adjustment, LeNet can be run on various input types, from grayscale digits to color images. Its small size also makes it ideal for testing low-latency inference on edge hardware.
This simplicity is why it’s often used to benchmark training pipelines or test quantization tools. It offers fast iteration and lets you focus on learning or debugging without waiting hours for feedback.
LeNet may seem outdated, but it’s still useful. It’s used in embedded systems and hardware where low memory and computing are priorities. With TensorFlow Lite or ONNX, LeNet can run on Raspberry Pi or microcontrollers, delivering real-time results without GPU support.

It’s also commonly used for visualizing internal model behavior. Feature maps from each layer can be plotted to show what the model sees, making it great for explaining CNNs. Educators rely on LeNet to teach students how layers stack, how filters extract patterns, and how dense layers make decisions.
LeNet also remains a standard benchmark for optimizers, loss functions, and training strategies. Whether you’re testing a new technique or debugging a toolchain, it offers quick feedback and consistent results.
Even in modern architectures, the basic principles from LeNet persist: small filters, layered abstraction, and spatial reduction. Many advanced CNNs simply repeat and expand on these concepts. So, understanding LeNet provides a strong foundation for working with more complex models later.
LeNet isn’t just a piece of history—it’s still useful today. Its clean structure, fast training, and adaptability make it valuable for learning, prototyping, and deployment on constrained hardware. Mastering LeNet gives you more than a working model; it helps you grasp the fundamentals of convolutional networks. From teaching to real-world applications, LeNet continues to serve a purpose, showing that sometimes, less is more when it comes to understanding how models learn and work.