Advertisement

How to use the SQL Update Statement with clear syntax, practical examples, and tips to avoid common mistakes. Ideal for beginners working with real-world databases

Discover 7 practical ways to get the most out of ChatGPT-4 Vision. From reading handwritten notes to giving UX feedback, this guide shows how to use it like a pro

How the Open Medical-LLM Leaderboard ranks and evaluates AI models, offering a clear benchmark for accuracy and safety in healthcare applications

Learn the regulatory impact of Google and Meta antitrust lawsuits and what it means for the future of tech and innovation.

Synthetic training data can degrade AI quality over time. Learn how model collapse risks accuracy, diversity, and reliability
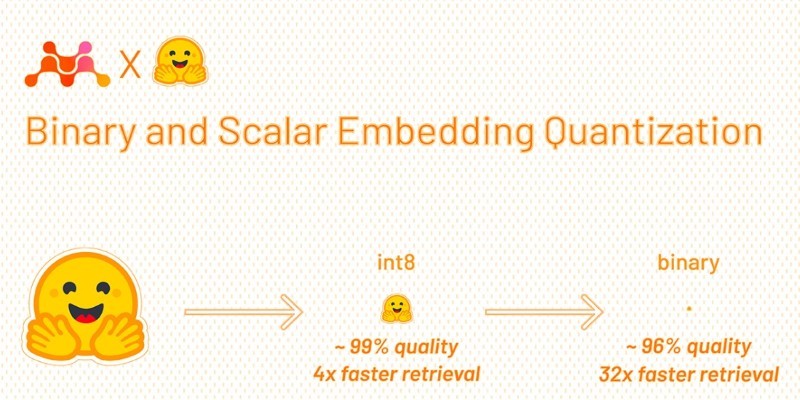
How Binary and Scalar Embedding Quantization for Significantly Faster and Cheaper Retrieval helps reduce memory use, lower costs, and improve search speed—without a major drop in accuracy

Explore Llama 3 by Meta, the latest open LLM designed for high performance and transparency. Learn how this model supports developers, researchers, and open AI innovation
Learn how to build a multi-modal search app that understands both text and images using Chroma and the CLIP model. A step-by-step guide to embedding, querying, and interface setup

What if online shopping felt like a real conversation? Shopify’s new AI agents aim to replace filters and menus with smart, personalized chat. Here’s how they’re reshaping ecommerce

Discover how ServiceNow uses AI to boost ROI, streamline workflows, and transform digital operations across your business

How to merge two dictionaries in Python using different methods. This clear and simple guide helps you choose the best way to combine Python dictionaries for your specific use case

Discover how Nvidia continues to lead global AI chip innovation despite rising tariffs and international trade pressures.
Large-scale search and retrieval systems rely on dense embeddings to match queries to documents, images, or other types of data. These embeddings are usually high-dimensional floating-point vectors, which use a lot of memory and are expensive to process at scale. As data grows and real-time retrieval becomes a stronger requirement, infrastructure costs and latency become concerns. That's where quantization comes in.
By shrinking the size of embeddings—without losing much accuracy—retrieval gets faster, and serving gets cheaper. Binary and scalar quantization are two promising methods to make this happen. Unlike older tricks like pruning or distillation, these methods focus on storage and compute efficiency with minimal changes to the model or data pipeline.
Binary quantization is the most aggressive form of embedding compression. Instead of storing embeddings as 32-bit or 16-bit floats, it forces each dimension into just a single bit. This results in a vector of 0s and 1s, which means a 768-dimension float embedding shrinks from around 3KB to just 96 bytes. This isn't just good for memory. It also allows extremely fast comparisons using bitwise operations like XOR and population count (popcount), which are natively supported by most modern CPUs.
In retrieval, you often want to find the closest vectors to a given query. With binary embeddings, this turns into computing Hamming distances. Since hardware can compute popcounts rapidly over 64-bit words, this leads to massive speed-ups. The downside is clear, though—binarizing a dense embedding can lead to some loss in accuracy. But with some clever tricks like optimized binarization layers, learned thresholds, or multi-bit binarization, the accuracy drop can be managed.
Where binary quantization really shines is when the number of items in your index goes into the tens or hundreds of millions. Memory savings compound and the simplicity of operations make it a great fit for real-time, CPU-only inference. It's especially useful when using smaller retrieval models or working in environments where GPUs are too costly or impractical.
Scalar quantization takes a more moderate approach. Instead of reducing each embedding dimension to 1 bit, it assigns each value to one of a fixed number of buckets. For example, in 8-bit quantization, each float in the embedding is rounded to one of 256 possible values. This is a well-known technique in areas like audio and image compression, and it's being used more and more in retrieval tasks, especially with dense vector databases.

What makes scalar quantization appealing is that it strikes a good tradeoff between performance and fidelity. Retrieval with scalar-quantized vectors can still use approximate nearest neighbour (ANN) algorithms like Product Quantization (PQ), IVF-PQ, or HNSW. These are fast and memory-efficient, and the quantization step doesn't hurt recall too much if calibrated properly.
Another advantage is compatibility. Scalar-quantized vectors can still work with common ANN libraries like FAISS or ScaNN. You don’t need to redesign your stack. Some retrieval systems even use hybrid quantization methods, where query vectors stay in float32 for better precision, but database vectors are quantized. This setup offers a solid mix of speed and quality while minimizing storage costs.
Scalar quantization also works well with post-training quantization tools like those in Hugging Face Optimum or ONNX Runtime. You don’t need to retrain your models from scratch—just quantize the embeddings before storing or indexing them.
Binary and scalar quantization are not interchangeable—they work best in different settings. Binary is about raw speed and ultra-light memory use. If your application can tolerate a small drop in accuracy and you care more about speed and scale, binary is the better choice. This includes real-time ranking, autocomplete, or edge-based search.
Scalar quantization is better when you still need decent accuracy, like in document retrieval or semantic search, where relevance matters more. It's also more flexible and easier to integrate into existing systems. You can experiment with different quantization levels (like 8-bit or 4-bit) to find the right balance for your setup.
The choice also depends on the model you're using to generate embeddings. Some newer architectures, like those trained with quantization-aware training or discrete latent variables, are more robust to being quantized. You can even train models from scratch with quantization in mind, leading to better outcomes with both binary and scalar approaches.
Quantization isn't just a neat trick—it has a real impact on retrieval workloads. Embedding quantization can reduce storage costs by 4x to 32x, depending on the method. This means smaller indexes, cheaper RAM or SSD requirements, and faster lookups. It also cuts down bandwidth costs if you're sending embeddings across services or networks.

In some benchmarks, using 8-bit scalar quantization led to a 2x increase in retrieval speed with less than a 1% drop in recall. Binary quantization gave a 10x speed-up but with a tradeoff of 3-5% in accuracy, depending on the dataset. The actual gains depend on the task and how embeddings are used—whether you're doing a similarity search, reranking, or filtering.
The impact is even greater when combined with other tricks like grouping, clustering, or caching hot queries. Some teams are also pairing quantization with learned indexes, where the structure of the search space is optimized along with the embeddings.
The idea is to treat quantization not as a final compression step but as a part of the model design itself. Instead of retrofitting quantization after the model is trained, newer systems think about fast retrieval from day one. This leads to better compatibility, less performance drop, and more predictable behaviour in production.
Binary and scalar embedding quantization offers two clear paths toward faster and cheaper retrieval at scale. One favours raw efficiency with minimal storage, while the other finds a middle ground between performance and accuracy. Both methods are reshaping how search systems are built, especially as data scales beyond what traditional float-based retrieval can handle. Quantization isn't just about compression—it's about making retrieval systems simpler, leaner, and more predictable under load. With growing interest in low-cost AI inference and edge computing, techniques like these are no longer optional. They're becoming the default.